Generative AI Research from arXiv: An Analysis of Key Publications from July 2025
- Shashank Shekhar
- Aug 9, 2025
- 10 min read

Updated: Aug 30, 2025


arXiv papers shows a field coming to terms with the unintended consequences of its own progress. The five themes that I track has been used as a filter to extract the listing of most important papers. In Creativity, the once-celebrated story of democratization is being re-examined, as researchers weigh the benefits of broader access against the risks of creative sameness. In Security and Privacy, long-standing assumptions are being challenged: practices like fine-tuning—once seen as routine—are now understood to introduce serious vulnerabilities. The discussion in Ethics and Accountability is also moving beyond surface-level demands for transparency, with scholars proposing new governance models to manage the risks posed by inherently opaque “black-box” systems. In Science, Medicine, and Education, the use of GenAI is shifting away from generic tools toward specialized, reasoning-capable partners designed to close the troubling “plausibility–validity gap.” In Technology and Systems, research on Hallucinations and Reliability is breaking the issue into smaller, more manageable subtypes, revealing that some of the most dangerous errors come from the system’s overconfidence and need to be addressed right from the training stage. Finally, work in Human–Computer Interaction and the Future of Work suggests that the old “human-in-the-loop” model is giving way to something more ambitious: a genuine human–AI partnership, or co-agency, that could reshape how we think about innovation, productivity, and even the nature of work itself.
Creativity
July- Papers
Paper1: Fanfiction in the Age of AI: Community Perspectives on Creativity, Authenticity and Adoption
Shifting the focus from the individual creator to the collective, this study investigates the perceptions of AI-generated content within the established creative community of fanfiction. The research examines how these human-centric communities, built on collaboration and shared values, react to the integration of GenAI. It probes their primary concerns regarding creativity, authenticity, and the potential erosion of community norms.
While acknowledging that human-GenAI co-creation has been shown to enhance individual creativity, the paper highlights significant and widespread community concerns. These include anxieties about authorship, the potential for AI to homogenize content, and the risk of eroding writers' creative autonomy and skills through over-reliance on the technology. A key fear identified is the influence of a "machine culture," where the AI tools themselves, through their biases and operational logic, begin to dictate which narratives are transmitted, potentially amplifying bias and reducing the originality and depth of human-driven storytelling. This research underscores that the adoption of GenAI is not merely a technical or individual choice but a profound socio-cultural issue. It demonstrates how the values of a creative community can clash with the affordances of a technology, posing challenges to the culture and dynamics of online creative spaces.
Offering a unique and personal perspective, this paper presents a first-person, reflective account of creating music albums using prompt-based AI. It directly confronts the artist's feelings of agency, originality, and even fraudulence in this new creative paradigm. The central question it explores is the subjective experience of a human creator in a co-creative process with AI. The work delves into how an artist negotiates concepts of authorship when the AI is a significant, and at times unpredictable, contributor to the final product. The author's project, which involved colliding "junk mail" with AI music platforms, serves as a creative probe to test the boundaries of the technology and explore new, unexpected musical spaces. This autoethnographic methodology provides rich, qualitative data on the psychological and philosophical challenges of human-AI collaboration. It moves the discussion beyond purely technical evaluations of output quality to the lived experience of creation.
This paper takes a critical look at the idea that GenAI music platforms like Suno, Udio, AIVA, and Stable Audio are "democratizing" music creation. Instead of focusing only on the technology, it examines the values and assumptions built into these systems by their developers and how users respond to them. The central question is whether these platforms truly open up music-making to everyone, or if the democratization narrative is more of a marketing strategy that hides deeper commercial and technological agendas which may, in fact, limit or reshape creativity.
The study of four major GenAI music systems in mid-2025 shows a more complicated picture. GenAI can act as anything from a simple tool to a creative partner, or even an autonomous creator, blurring its role in the artistic process. This uncertainty lies at the heart of current debates about its impact. By linking today’s GenAI boom to past waves of automation, like the industrial revolution, the paper highlights recurring concerns: the loss of human jobs, the erosion of skilled craftsmanship, and the risk of undervaluing human agency. This historical perspective challenges the overly optimistic promises of tech developers and calls on researchers and practitioners to approach these tools with caution and foresight.
This study introduces and investigates the concept of "narrow creativity," a potential limitation that may affect both human and AI creative processes. The research addresses a fundamental question: Does GenAI truly expand the creative search space, or does it, like humans, tend to operate within a limited, familiar subset of possibilities? This inquiry challenges the popular narrative of AI as a boundless source of novelty.
Using the "Circles Exercise," a standardized creativity test, the study conducts a comparative analysis of human and GenAI outputs. The results are revealing: humans tend to generate familiar, high-frequency ideas, while GenAI excels at producing a high volume of incremental innovations within a given set of constraints. The paper concludes that GenAI exhibits similar patterns of narrow creativity to humans, struggling to autonomously generate "radical creativity" that goes beyond its training. This finding is critical for setting realistic expectations for GenAI's role in creative fields such as art, design, and music composition.
AI in Education
July-Papers
The paper breaks down the challenges as follows:
Accuracy: The risk of AI hallucinations and the propagation of subtle errors is a primary concern, as these can mislead students and undermine the learning of fundamental concepts.
Authenticity: The ease with which AI can generate code and explanations blurs the line between authentic student work and AI-assisted output. This poses a direct threat to the development of students' own critical thinking and problem-solving skills.
Assessment: While efficient, AI-driven grading tools may struggle to evaluate more nuanced aspects of student work like creativity and elegant problem-solving. They can also perpetuate and scale biases present in their training data.
The paper's overarching recommendation is not to ban these tools, but to pursue a balanced, hybrid approach. This involves actively promoting AI literacy for both students and educators, implementing human-in-the-loop systems for oversight, and redesigning assessment methods to prioritize tasks that require genuine student understanding, such as oral presentations, reflective essays, and in-person problem-solving sessions.
Assessing if fine-tuned open-source LLMs can serve as viable pedagogical tools compared to proprietary models. Confirms the viability of open-source models, promoting democratization of AI in education.
AI Ethics and Security
July-Papers
This paper argues that the way the security community has been cataloging threats against Large Language Models (LLMs) is insufficient for the real world. It observes that existing taxonomies, which focus on attack techniques like prompt injection or data poisoning, fail to capture the strategic intent behind an attack. To remedy this, the research proposes a novel, objective-driven taxonomy that offers a more robust framework for anticipating and mitigating threats. Anyone starting on LLM security, should read this paper, first.
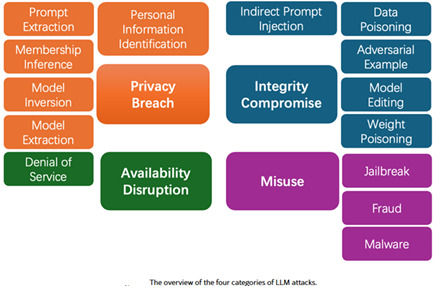
This is a positioning paper, arguing that its time to expand the data poisoning attack system, from threat specific approach – access to training data, access to LLM etc.; to multifaceted approach -



Paper3: CyberLLMInstruct: A New Dataset for Analysing Safety of Fine-Tuned LLMs Using Cyber Security Data
Using the OWASP Top 10 for Large Language Models framework as a benchmark, the study rigorously assesses the safety of fine-tuned models and finds that the process consistently reduces safety resilience across all tested LLMs and for every type of adversarial attack. The paper provides a dramatic and quantifiable example: the security score of the Llama 3.1 8B model against prompt injection attacks plummeted from a highly resilient 0.95 to a very vulnerable 0.15 after being fine-tuned. This is a critical finding because it reveals that a process intended to improve a model's performance for a specific task can simultaneously and catastrophically degrade its security posture. This highlights the urgent need for new, security-aware fine-tuning techniques.

This paper introduces a novel philosophical and practical approach to AI accountability, designed specifically for the challenges posed by complex, opaque generative models. The core research problem it tackles is fundamental: How can we establish accountability for AI systems whose internal mechanisms are so complex that even their creators cannot fully trace the reasons for a given output?

This systematic mapping study provides a comprehensive, evidence-based overview of the ethical landscape for LLMs, categorizing the primary concerns and critically assessing the state of proposed solutions. The research addresses the fragmented nature of the discourse on LLM ethics by conducting a systematic analysis to identify the most prominent ethical dimensions, categorize existing mitigation strategies, and, most importantly, pinpoint the gaps between theory and practice.
AI in Scientific Research
July-Papers:
LLMs often generate scientifically plausible but factually invalid information, particularly in specialized domains like chemistry. This paper presents a systematic methodology to bridge this gap by developing a specialized scientific assistant. By combining a reasoning-centric model architecture with intensive domain-specific fine-tuning, the researchers were able to create a specialist model that effectively bridges the gap.

The study finds that while GenAI shows promise for certain scientometric tasks like automatically labeling research topics, it struggles with tasks that require stable semantics, pragmatic reasoning, or structured domain knowledge. However, its most profound and forward-looking contribution is its inquiry into whether GenAI will fundamentally alter the objects of measurement themselves. If AI becomes a significant contributor to writing papers, it could destabilize the meaning of core concepts like "author," "citation," and "intellectual contribution." This would force the field of scientometrics, and indeed the entire academic community, to redefine how scientific progress is measured and attributed in an age of human-machine collaboration.
This paper explores a practical solution to the problem of hallucinations in the high-stakes domain of radiology question-answering, where factual accuracy is paramount. The research problem is to find an effective way to improve the factual reliability and diagnostic accuracy of LLMs in clinical settings, where a hallucinated response could have severe consequences for patient care. The study implements and tests an agentic retrieval framework. This system goes beyond simple Retrieval-Augmented Generation (RAG) by endowing the AI with the agency to actively decide when it needs more information and what specific information it needs to retrieve from an external knowledge base to ground its response. The results demonstrated the framework's effectiveness: agentic retrieval significantly reduced the rate of hallucinations (by a mean of 9.4%) and substantially improved the model's ability to retrieve clinically relevant context to support its answers (doing so in 46% of cases). Notably, the improvements were most pronounced in small and mid-sized models. This suggests that agentic frameworks can be a powerful and computationally efficient way to make less powerful, more accessible models safer and more useful in specialized, high-risk domains.

AI in Technology and Systems
July-Papers:
Sensitivity Dropout (SenD). This technique works by deterministically identifying and dropping embedding indices that exhibit high variability during training, effectively "detoxing" the model from the unstable components that are likely to lead to hallucinations. The results are significant: SenD was shown to improve the test-time reliability and factual accuracy of models from the Pythia and Llama families by up to 17%. Crucially, this improvement came without degrading performance on standard downstream benchmark tasks. This represents a major step forward, offering a practical path toward building more factual and trustworthy models from the ground up, rather than relying solely on post-hoc patches and filters.


This research directly challenges one of the core assumptions in the study of hallucinations: the idea that they are primarily associated with model uncertainty. The paper investigates a more insidious question: Are all hallucinations a product of a model's uncertainty, or can a model be confidently and persuasively wrong?
The findings reveal a critical and dangerous failure mode. The study demonstrates that LLMs can and do hallucinate with high certainty, even in cases where they possess the correct knowledge internally. These "high-certainty hallucinations" are not random noise; the paper shows they are consistent across different models and datasets, suggesting they are a systematic, not an idiosyncratic, problem. This discovery has profound implications for safety and mitigation. Many proposed strategies for dealing with hallucinations rely on uncertainty estimation—for example, having the model abstain from answering or flag its response when its confidence is low. Such methods would be completely ineffective against these confident errors, as the model would see no reason to doubt its incorrect output.
The authors postulate that GenAI's true power lies not in doing existing tasks faster, but in its ability to catalyze exploratory and combinatorial innovation. It proposes a human-complementary approach where GenAI is leveraged as a generative partner to radically increase creativity, experimentation, and growth, rather than simply as a tool for optimization. A critical dimension identified in this new paradigm is GenAI's "democratizing effect." The paper suggests that if human agency is prioritized in its implementation, GenAI can amplify mechanisms for widely shared growth by empowering employees at all levels to participate in innovation.
The paper introduces "DesignFromX," a system that enables consumers to actively participate in the design exploration of products simply by prompting a generative model. A user study demonstrated that this approach lowered barriers and reduced frustration, significantly enhancing both engagement and enjoyment for the participants.
Conclusion:
July papers highlights several persistent challenges that will define the next frontier of GenAI development. The practical validation of security threats remains a critical gap; the security community must move toward developing threat models that are rigorously grounded in the realities of enterprise-level MLOps. In ethics, the development of robust, standardized, and enforceable governance frameworks is paramount; the leap from high-level principles to auditable, practical implementation has yet to be made. Finally, understanding the long-term societal and economic impacts of human-AI symbiotic work—on wages, skill valuation, and organizational structures—remains a vast and vital area for future interdisciplinary research.


Comments